After getting positive feedback from Output Messenger v1.0 customers, we are planning to press the accelerator further to make sure all features in instant messaging world is available in our Output Messenger too.
One of the request from customers is a hosted version. Our existing architecture is designed as a self-hosted version & scalable to support 10,000 users inside a company. But for a cloud based hosted version, obviously needs more scalability & availability.
While designing the needed changes in existing design, need to choose a scalable database to store the chat message history. As there will be more write operations, we preferred Log Structured Merge tree (LSM Tree) & started reviewing few databases.
The top in our review list was "Cassandra"
Apache Cassandra - A linear scalable database designed for high performance best in class Write & Read, with scalability & availability.
Cassandra's database is designed as a master less architecture with fully distributed & therefore no single-point-of-failure (SPOF).
The Write record gets replicated across multiple nodes & so there is no master / slave node. Even it gets replicated across multiple nodes, the client will wait for only one node confirmation.
Also by having LSM Tree structure, the insert data will be kept in memory, later it will be appended in disk & merged. So, Write operations will be fast without waiting for any index ordering.
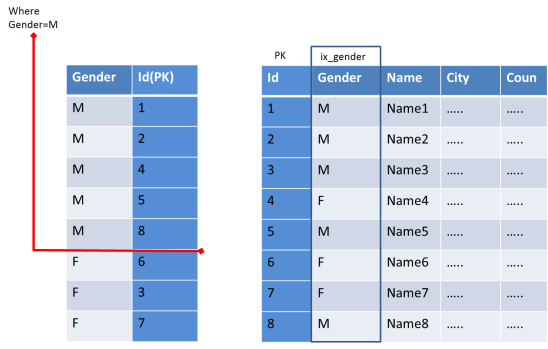
Another important advantage with Cassandra is their column indexes.
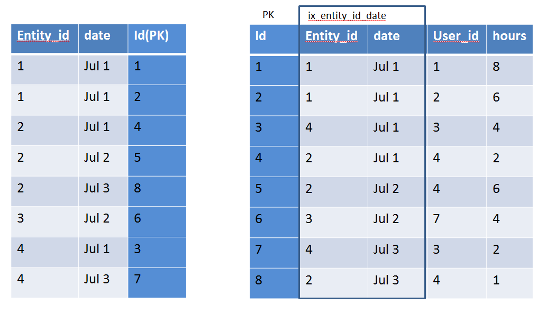
Let's see how a Composite-keyed index (primary key + column index(s)) may help for our instant messenger chat history logs.
Assume we are having the chat history table structure as below:
While querying
select * from chatmessages
It seems to be normal database result/operations. We may assume data is also stored in this format.
But, the interesting part is Cassandra stores in its own way.
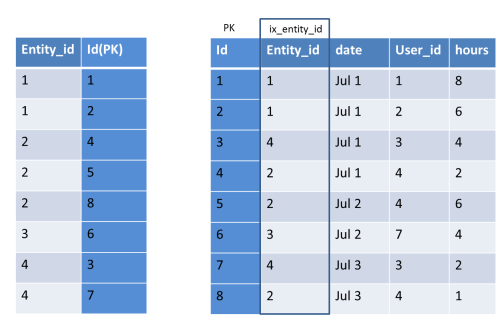
Of the 4 columns declared in create table, will result as 2 columns while insert operation.
row_key : chatroomid (first key declared in primary key)
column_name_1: senton + from (from value will be stored in this column)
column_name_2: senton + message (message value will be stored in this column)
ie, The first of Primary key will be the row key. Subsequent primary key column values will be the prefix of the non-primary columns.
As below our data look in Cassandra's storage model:
The columns keep on growing with messages.
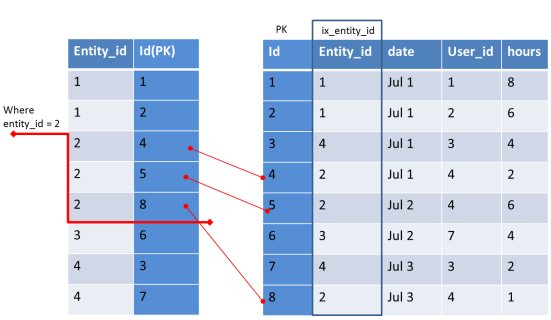
While fetching chat room messages for a particular period, our select query will be:
select * from chatmessages where chatroomid=1241 and senton >= '2014-11-13 00:00:00+0200' AND senton <= '2014-11-20 23:59:00+0200'
We have to always use chatroomid in filter as it is the main row key.
Also Cassandra has CQL (Cassandra Query Language) much similar to SQL, which gives familiar way to develop back end.
With all these advantages in consideration, let's wait & see, can Cassandra join with our Output Messenger family tools.
Happy Messaging!
One of the request from customers is a hosted version. Our existing architecture is designed as a self-hosted version & scalable to support 10,000 users inside a company. But for a cloud based hosted version, obviously needs more scalability & availability.
While designing the needed changes in existing design, need to choose a scalable database to store the chat message history. As there will be more write operations, we preferred Log Structured Merge tree (LSM Tree) & started reviewing few databases.
The top in our review list was "Cassandra"
Apache Cassandra - A linear scalable database designed for high performance best in class Write & Read, with scalability & availability.
Cassandra's database is designed as a master less architecture with fully distributed & therefore no single-point-of-failure (SPOF).
The Write record gets replicated across multiple nodes & so there is no master / slave node. Even it gets replicated across multiple nodes, the client will wait for only one node confirmation.
Also by having LSM Tree structure, the insert data will be kept in memory, later it will be appended in disk & merged. So, Write operations will be fast without waiting for any index ordering.
Another important advantage with Cassandra is their column indexes.
Let's see how a Composite-keyed index (primary key + column index(s)) may help for our instant messenger chat history logs.
Assume we are having the chat history table structure as below:
create table chatmessages (
chatroomid int,
senton timestamp,
sender varchar,
message varchar,
PRIMARY KEY (chatroomid, senton)
);
While querying
select * from chatmessages
| chatroomid | senton | from | message |
| 1241 | 12569537329 | ram | Hi |
| 1241 | 12569537411 | laxman | Hi Ram,How ar.. |
| 1241 | 12569537523 | ram | Fine..I need a.. |
| 1241 | 12569537758 | laxman | Yes. Sure. I can … |
It seems to be normal database result/operations. We may assume data is also stored in this format.
But, the interesting part is Cassandra stores in its own way.
Of the 4 columns declared in create table, will result as 2 columns while insert operation.
row_key : chatroomid (first key declared in primary key)
column_name_1: senton + from (from value will be stored in this column)
column_name_2: senton + message (message value will be stored in this column)
ie, The first of Primary key will be the row key. Subsequent primary key column values will be the prefix of the non-primary columns.
As below our data look in Cassandra's storage model:
| chatroomid | 12569537329 from | 12569537329 message | 12569537411 from | 12569537411 message | … |
| 1241 | ram | Hi | laxman | Hi Ram,H.. | … |
The columns keep on growing with messages.
While fetching chat room messages for a particular period, our select query will be:
select * from chatmessages where chatroomid=1241 and senton >= '2014-11-13 00:00:00+0200' AND senton <= '2014-11-20 23:59:00+0200'
We have to always use chatroomid in filter as it is the main row key.
Also Cassandra has CQL (Cassandra Query Language) much similar to SQL, which gives familiar way to develop back end.
With all these advantages in consideration, let's wait & see, can Cassandra join with our Output Messenger family tools.
Happy Messaging!